SSL: Sound Source Localization and Discrimination
Description
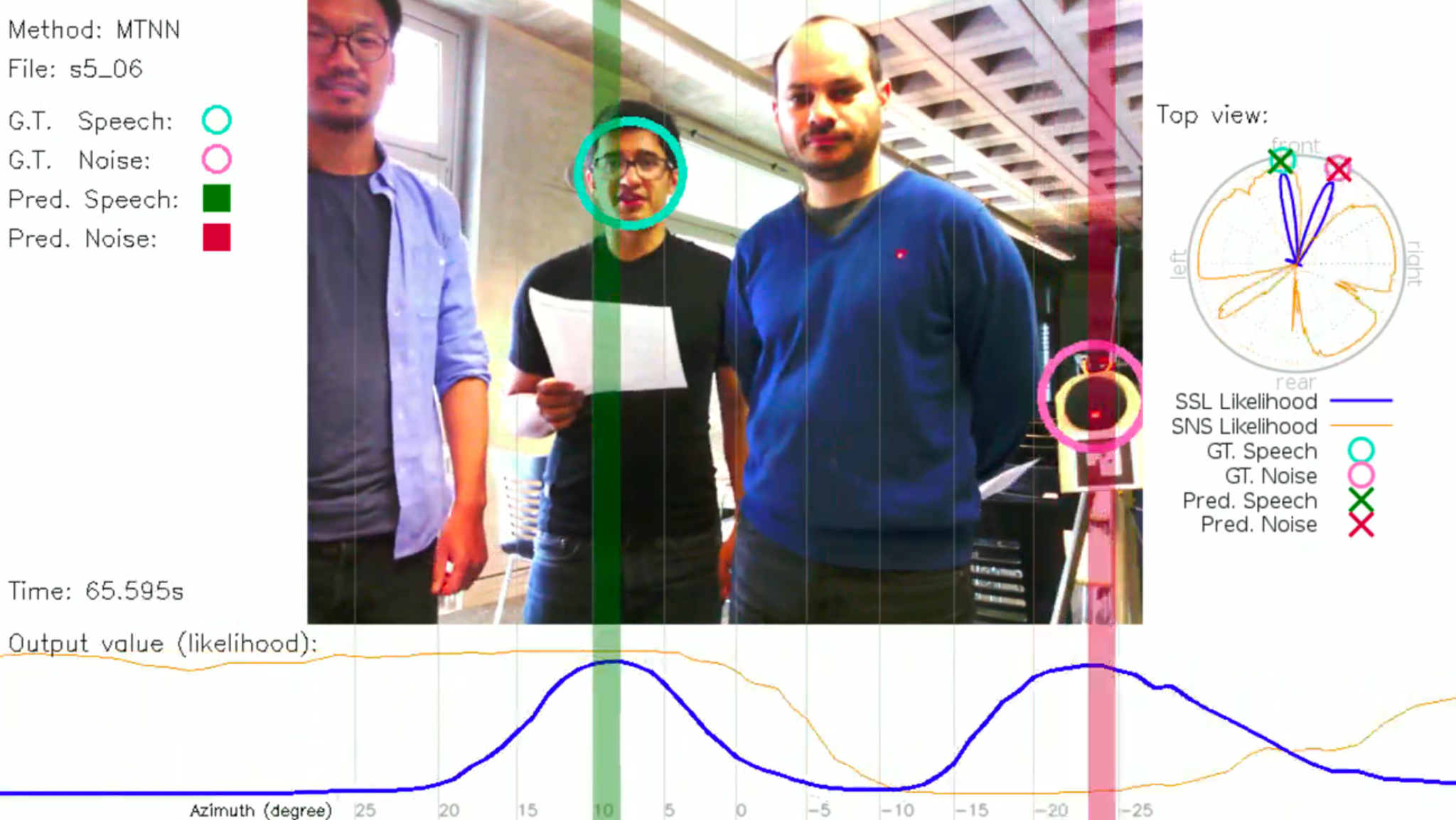
We have pioneered the first viable deep learning framework (task definition, network architecture, training paradigm) for solving fundamental auditory tasks such as sound source localization, speaker identification and speech/non-speech classification. The framework is suitable for highly noisy environments and overcomes limitations of previous methods, which heavily relied on idealized sound and environment models and are inadequate for everyday situations with multiple sound sources, background noise, short utterances, and lack of prior knowledge of the number of sound sources. The method learns sound source localization models with limited training resources leveraging simulated and weakly-labeled real audio data.
Publications
- He, W. and Motlicek, P. and Odobez, J-M. (2021) Multi-task Neural Network for Robust Multiple Speaker Embedding Extraction. Interspeech 2021
- He, W. and Motlicek, P. and Odobez, J-M. (2021) Neural Network Adaptation and Data Augmentation for Multi-Speaker Direction-of-Arrival Estimation. IEEE/ACM Transactions on Audio, Speech, and Language Processing
Links
Advantages
- Robust localization and identification methods
- Working in noisy environments
Applications
Any application which needs to localize and identify speakers
Technology Readiness Level
TRL 6
Contact us for more information
- Interested in using our technologies?
- Interested to know more about the licensing possibilities and conditions?