Face Recognition with Knowledge Distillation from Synthetic Data
Description
Training face recognition models also requires large identity-labeled datasets. Meanwhile, there are privacy and ethical concerns with collecting and using large face recognition datasets. While generating synthetic datasets for training face recognition models is an alternative option, it is challenging to generate synthetic data with sufficient intra-class variations. In addition, there is still a considerable gap between the performance of models trained on real and synthetic data.
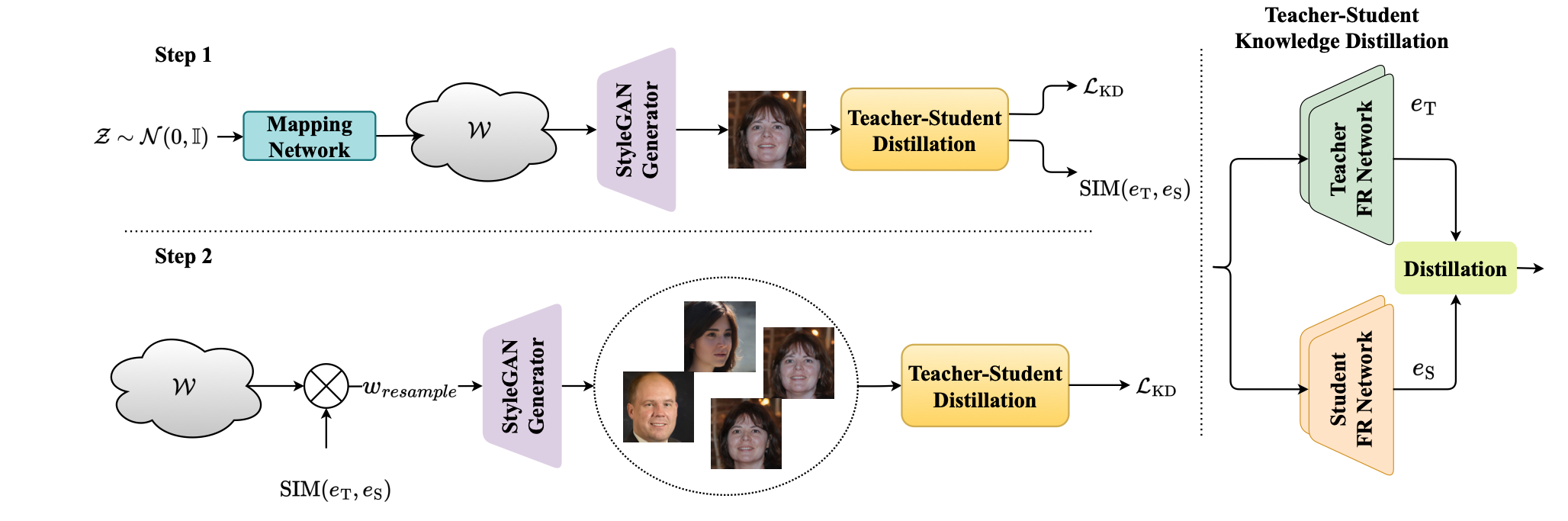
We proposed a new framework (named SynthDistill) to train lightweight face recognition models by distilling the knowledge of a pretrained teacher face recognition model using synthetic data.
Publications
Krivokuca, V. and Otroshi Shahreza, H. and George, A. and Marcel, S. (2023). SynthDistill: Face Recognition with Knowledge Distillation from Synthetic Data. IEEE International Joint Conference on Biometrics (IJCB 2023).
Links
Advantages
We use a pretrained face generator network to generate synthetic face images and use the synthesized images to learn a lightweight student network. We use synthetic face images without identity labels, mitigating the problems in the intra-class variation generation of synthetic datasets. The results on five different face recognition datasets demonstrate the superiority of our lightweight model compared to models trained on previous synthetic datasets, achieving a verification accuracy of 99.52% on the LFW dataset with a lightweight network. The results also show that our proposed framework significantly reduces the gap between training with real and synthetic data.
Applications
- Face Recognition
Technology Readiness Level
TRL 5
Contact us for more information
- Interested in using our technologies?
- Interested to know more about the licensing possibilities and conditions?